
Bijblijven in een snel evoluerende industrie als kunstmatige intelligentie is een zware taak. Dus om AI het voor u te laten doen, volgt hier een handige samenvatting van de verhalen van de afgelopen week in de wereld van machine learning, samen met opmerkelijk onderzoek en experimenten die we niet alleen zouden behandelen.
In een van de meest verrassende verhalen van de afgelopen week heeft de Italiaanse gegevensbeschermingsautoriteit (DPA) de door AI aangedreven chatbot van OpenAI, ChatGPT, verboden, daarbij verwijzend naar bezorgdheid dat de tool in strijd is met de algemene verordening gegevensbescherming van de Europese Unie. Het ministerie van Politieke Zaken zou een onderzoek openen naar de vraag of OpenAI de gegevens van mensen illegaal verwerkte, evenals het ontbreken van een systeem om te voorkomen dat minderjarigen toegang krijgen tot de technologie.
Het is onduidelijk wat de uitkomst zou kunnen zijn; OpenAI heeft 20 dagen de tijd om op het verzoek te reageren. Maar de stap van de DPA kan grote gevolgen hebben voor bedrijven die machine learning-modellen inzetten, niet alleen in Italië, maar overal in de Europese Unie.
leuk vinden Natasha Aantekeningen in haar nieuwsartikel Verschillende OpenAI-modellen zijn getraind op gegevens die van internet zijn gehaald, waaronder sociale netwerken zoals Twitter en Reddit. Ervan uitgaande dat hetzelfde geldt voor ChatGPT, aangezien het bedrijf de mensen wiens gegevens het opnieuw heeft toegewezen niet lijkt te hebben geïnformeerd om de AI te trainen, is het waarschijnlijk in strijd met de AVG over de hele linie.
De Algemene Verordening Gegevensbescherming (AVG) is een van de vele potentiële juridische hindernissen waarmee AI wordt geconfronteerd, met name generatieve AI (bijvoorbeeld tekst- en kunstgeneratie zoals ChatGPT). Met elke groeiende uitdaging werd het duidelijker dat het even zou duren voordat het stof was neergedaald. Maar dat schrikt venture-investeerders niet af, die kapitaal in de technologie blijven steken alsof er geen morgen is.
Zullen dit verstandige investeringen of toezeggingen blijken te zijn? Moeilijk te zeggen momenteel. Maar wees gerust, we zullen verslag uitbrengen over alles wat er gebeurt.
Hier zijn andere AI-koppen die de afgelopen dagen zijn opgemerkt:
- Advertenties komen naar Bing Chat: Microsoft zei vorige week dat het aan het “verkennen” was om advertenties te plaatsen in reacties van Bing Chat, de zoekproxy die wordt aangedreven door het GPT-4-taalmodel van OpenAI. Zoals Devin opmerkt, hoewel gesponsorde reacties duidelijk als zodanig zijn gecategoriseerd, is het een nieuwere en misschien meer storende vorm van reclame die misschien niet gemakkelijk kan worden geïdentificeerd – of genegeerd. Bovendien kan het het vertrouwen in taalmodellen aantasten, die al genoeg feitelijke fouten maken om twijfel te zaaien over de juistheid van hun antwoorden.
- Pauze verzoek: Een brief met meer dan 1.100 ondertekenaars, waaronder Elon Musk, die dinsdag werd gepubliceerd, roept op tot “alle AI-labs om onmiddellijk te stoppen voor ten minste zes maanden met het trainen van AI-systemen die krachtiger zijn dan GPT-4.” Maar de omstandigheden om hem heen bleken duisterder dan men zou verwachten. In de daaropvolgende dagen trokken enkele ondertekenaars hun standpunt in, terwijl uit rapporten bleek dat andere spraakmakende ondertekenaars, zoals de Chinese president Xi Jinping, nep bleken te zijn.
- en reageren op het verzoek om een tijdelijke schorsingToonaangevende AI-ethici wijzen erop dat zorgen maken over hypothetische kwesties gevaarlijk en zelfvernietigend is als we de problemen waar AI vandaag de dag aan bijdraagt niet aanpakken.
- Twitter onthult zijn algoritme: Zoals keer op keer beloofd Volgens Twitter-CEO Elon Musk heeft Twitter geopend Een deel van de broncode staat open voor openbaar onderzoek, inclusief het algoritme dat wordt gebruikt om tweets aan te bevelen aan de tijdlijnen van gebruikers. Interessant is dat Twitter tweets gedeeltelijk lijkt te rangschikken door een neuraal netwerk te gebruiken dat constant wordt getraind op tweet-interacties om positieve betrokkenheid, zoals vind-ik-leuks en antwoorden, te verbeteren. Maar er zijn veel nuances, zoals onderzoekers gaten in de databasenota.
- Samenvattende vergaderingen met AI: In navolging van bedrijven als Otter en Zoom heeft de slimme vergaderingslezer een nieuwe functie geïntroduceerd die een vergadering van een uur in een fragment van twee minuten snijdt, vergezeld van belangrijke aanwijzingen. Het bedrijf zegt dat het grote taalmodellen gebruikt – die het niet specificeerde – samen met video-analyse om de hoogtepunten van een vergadering te selecteren, wat een handige functie is.
Meer machinaal leren
In Nvidia’s AI-enabler is Bionemo een voorbeeld van zijn nieuwe strategie, waarbij de vorderingen niet nieuw zijn, maar steeds toegankelijker worden voor bedrijven. De nieuwe versie van dit biotechnologieplatform voegt een gelikte webgebruikersinterface toe en verbeterde afstemming op een reeks formulieren.
“Een toenemend deel van pijpleidingen heeft te maken met stapels gegevens, hoeveelheden die we nog nooit eerder hebben gezien, honderden miljoenen sequenties die we in deze modellen moeten invoeren”, zegt Peter Grandsard van Amgen, die een onderzoeksafdeling leidt die AI-technologie gebruikt. . “We proberen net zoveel operationele efficiëntie te krijgen in onderzoek als in productie. Met de versnelling die technologie zoals Nvidia biedt, wat je vorig jaar voor één project had kunnen doen, kun je nu vijf of tien doen met dezelfde investering.” bij technologie.”
Dit fragment uit het boek van Meredith Brossard bij Wired is het lezen waard. Ze was nieuwsgierig naar het AI-model dat werd gebruikt bij haar diagnose van kanker (het gaat goed met haar) en vond het ongelooflijk zinloos en frustrerend om te proberen eigenaar te worden en deze gegevens en dit proces te begrijpen. Het is duidelijk dat medische AI-operaties de patiënt meer moeten bestuderen.
Negatieve toepassingen van kunstmatige intelligentie leiden juist tot nieuwe gevaren, bijvoorbeeld het proberen het discours te beïnvloeden. We hebben gezien wat GPT-4 kan doen, maar het was een open vraag of een dergelijk model effectieve overtuigende tekst zou kunnen creëren in een politieke context. De studie van Stanford University suggereert dit: wanneer proefpersonen werden blootgesteld aan case-artikelen over kwesties als wapenbeheersing en koolstofbelastingen, “waren de door AI gegenereerde berichten over alle onderwerpen minstens even overtuigend als de door mensen gegenereerde berichten.” Deze berichten werden ook als redelijker en realistischer gezien. Zal door AI gegenereerde tekst iemand van gedachten doen veranderen? Het is moeilijk te zeggen, maar het lijkt zeer waarschijnlijk dat mensen het steeds vaker voor dit soort agenda’s zullen gebruiken.

Voorbeelden van tekst die wordt gebruikt om te zien of AI overtuigend kan zijn.
Machine learning is door een andere groep aan de Stanford University gebruikt om de hersenen beter te simuleren – zoals in de weefsels van het orgaan zelf. Niet alleen zijn de hersenen complex en heterogeen, legde professor Eileen Cole uit in een persbericht, maar het lijkt “veel op Jell-O, wat het testen en modelleren van fysieke effecten op de hersenen erg moeilijk maakt.” Hun nieuwe model kiest en kiest uit duizenden methoden voor hersenmodellering, mixen en matchen om de beste manier te bepalen om de gegeven gegevens te interpreteren of weer te geven. Het vindt het modelleren van hersenbeschadiging niet opnieuw uit, maar het zou elke studie ervan sneller en effectiever moeten maken.
In de natuurlijke wereld is Fraunhofer’s nieuwe benadering van ML seismische beeldvorming van toepassing op een bestaande datapijplijn die terabytes aan output van hydrofoons en luchtbuks verwerkt. Normaal gesproken moeten deze gegevens worden vereenvoudigd of geabstraheerd, waardoor een deel van hun betrouwbaarheid in het proces verloren gaat, maar het nieuwe door ML aangedreven proces maakt niet-gereduceerde datasetanalyse mogelijk.
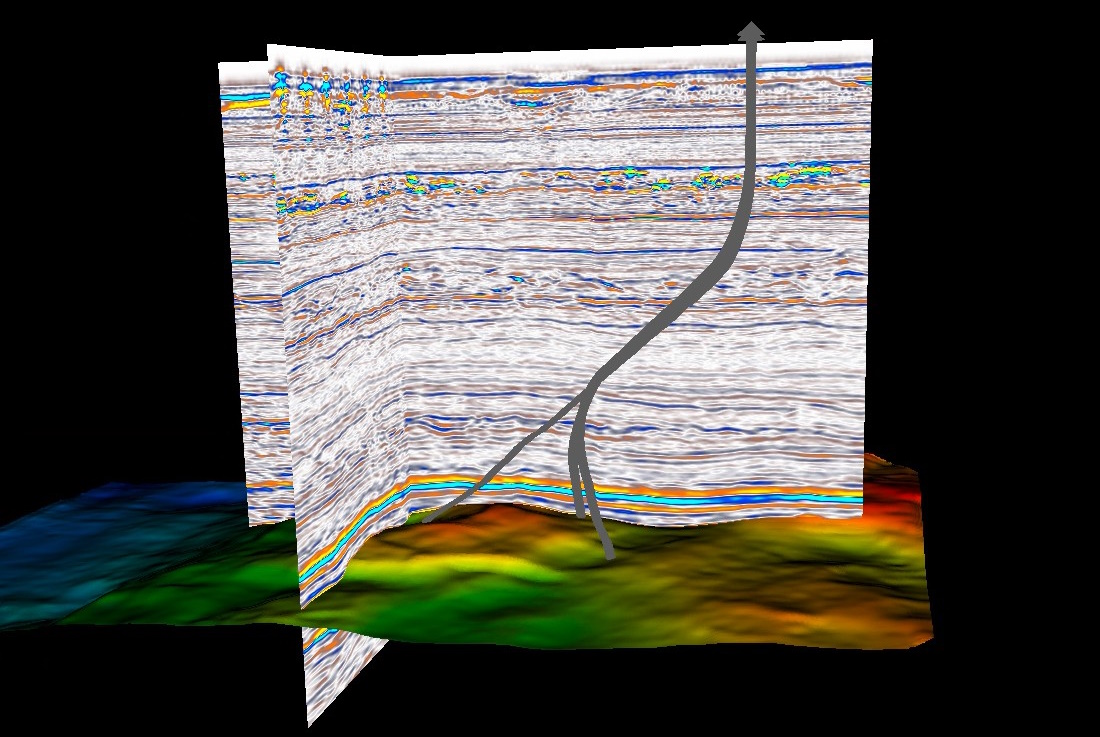
Afbeeldingscredits: Fraunhofer
Interessant is dat de onderzoekers opmerken dat dit normaal gesproken een zegen zou zijn voor olie- en gasbedrijven die op zoek zijn naar afzettingen, maar naarmate ze afstand nemen van fossiele brandstoffen, zou het kunnen worden gebruikt voor meer klimaatgeschikte doeleinden, zoals het identificeren van potentiële opslaglocaties voor koolstofdioxide of mogelijk schadelijke gassen. opstapelen.
Het monitoren van bossen is een andere belangrijke taak voor onderzoek naar klimaat en natuurbehoud, en het schalen van bomen is daar een onderdeel van. Maar deze taak omvat het handmatig één voor één controleren van de bomen. Een team in Cambridge heeft een ML-model gebouwd dat een lidar-sensor van een smartphone gebruikt om de diameter van een torso te schatten, na training op een reeks handmatige metingen. Richt gewoon de telefoon op de bomen om je heen en boem. Het systeem is tot vier keer sneller, zei de hoofdauteur van het onderzoek, Amelia Holcombe, maar toch nauwkeuriger dan hun verwachtingen: “Ik was verrast dat de app zo goed werkte. Soms daag ik het graag uit met een bijzonder druk stuk bos, of een vreemd gevormde boom.” Privé, en ik denk dat er geen manier is om het goed te maken, maar dat doet het wel.”
Omdat het snel is en geen speciale training vereist, hoopt het team dat het op grote schaal kan worden vrijgegeven als een manier om gegevens te verzamelen voor boomonderzoeken, of om bestaande inspanningen sneller en gemakkelijker te maken. Voorlopig alleen Android.
Geniet ten slotte van dit interessante onderzoek en experiment van Eigil zu Tage-Ravn om te zien hoe een kunstmodel ontstaat uit het beroemde schilderij in Spouter-Inn, beschreven in hoofdstuk 3 van Moby-Dick.

Afbeeldingscredits: Beoordeling in het publieke domein