
Het schrijven van een rapport over de staat van AI zou zoiets moeten zijn als bouwen op drijfzand: tegen de tijd dat je het publiceert, zal de hele branche onder je voeten zijn verschoven. Maar er zijn nog steeds belangrijke trends in de 386 pagina’s tellende poging van Stanford om dit complexe en snel evoluerende veld samen te vatten.
De AI Index, van het Institute for Human-Centered Artificial Intelligence, werkte samen met experts uit de academische wereld en de particuliere sector om informatie en voorspellingen over de kwestie te verzamelen. Als een jaarlijkse inspanning (en gezien de omvang kun je er zeker van zijn dat ze al hard werken om de volgende samen te stellen), is dit misschien niet het nieuwste experiment op het gebied van AI, maar deze periodieke, grootschalige enquêtes zijn belangrijk om door te gaan je vinger. Aan de pols van de branche.
Het rapport van dit jaar bevat “nieuwe analyse van fundamentele modellen, inclusief geopolitiek en opleidingskosten, de milieu-impact van AI-systemen, K-12 AI-onderwijs en publieke opinietrends in AI”, evenals een blik op de politiek in 100 nieuwe landen.
Laten we het hier opschrijven voor het hoogste niveau van afhaalmaaltijden:
- De ontwikkeling van kunstmatige intelligentie in het afgelopen decennium is met een grote marge omgeslagen van academisch leiderschap naar de industrie, en er is geen teken van verandering.
- Het is moeilijk geworden om modellen te toetsen aan traditionele normen en hier kan een nieuw model nodig zijn.
- De energievoetafdruk voor training en het gebruik van AI is groot, maar we hebben nog niet gezien hoe het elders efficiëntie kan toevoegen.
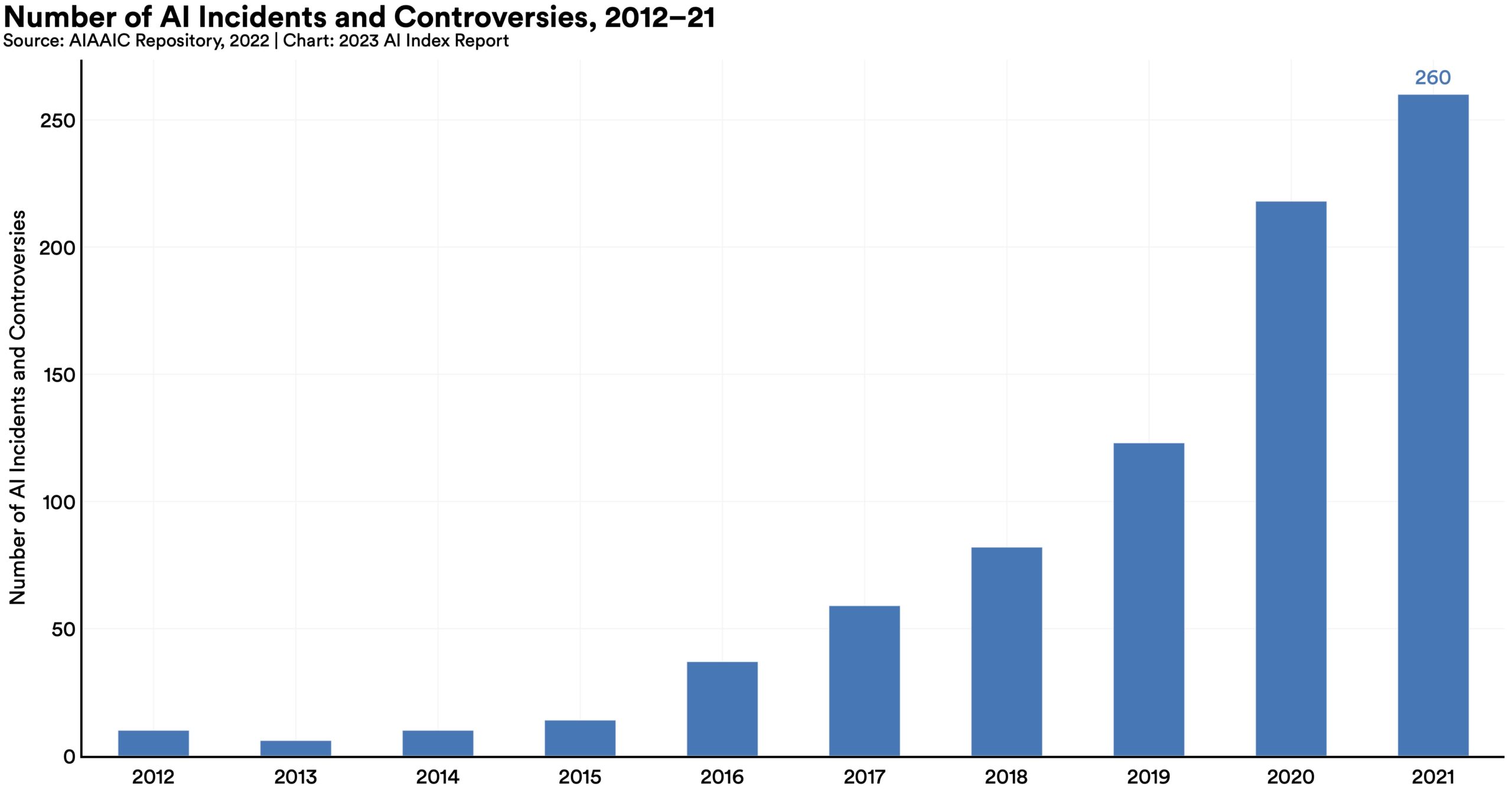
- Het aantal “AI-gerelateerde incidenten en geschillen” is sinds 2012 26 keer zo hoog geworden, wat eigenlijk wat laag lijkt.
- AI-gerelateerde vaardigheden en vacatures groeien, maar niet zo snel als je zou denken.
- Toch worstelen beleidsmakers om te proberen een definitieve AI-factuur te schrijven, een dwaze onderneming als die er al is.
- Investeringen zijn gepauzeerd, maar dit is na een astronomische toename in het afgelopen decennium.
- Meer dan 70% van de Chinese, Saoedische en Indiase deelnemers vond dat AI meer voordelen dan nadelen heeft. Amerikanen? 35%.
Maar het rapport gaat in detail over veel onderwerpen en subonderwerpen, en is gemakkelijk te lezen en niet-technisch. Alleen een allocator kan alle 300 oneven pagina’s lezen, maar eigenlijk kan elk opgewonden lichaam lezen.
Laten we hoofdstuk 3, Technische AI-ethiek, wat gedetailleerder bekijken.
Het is moeilijk om vooringenomenheid en toxiciteit terug te brengen tot statistieken, maar voor zover we modellen voor deze dingen kunnen identificeren en testen, is het duidelijk dat “ongefilterde” modellen veel gemakkelijker naar problematisch gebied kunnen leiden. Het aanpassen van de instructie, dat wil zeggen het toevoegen van een extra setuplaag (zoals een daemon-prompt) of het doorgeven van de uitvoer van het model aan een tweede tussenmodel, is effectief om dit probleem te verbeteren, maar het is verre van perfect.
Deze grafiek illustreert het beste de toename van “AI-gerelateerde incidenten en controverses” waar de kogels naar verwezen:
Afbeeldingscredits: Stanford Hallo
Zoals je kunt zien, is de trend opwaarts en deze cijfers kwamen vóór de algemene acceptatie van ChatGPT en andere grote taalparadigma’s, om nog maar te zwijgen van de enorme verbetering in beeldgeneratoren. U kunt er zeker van zijn dat de toename van 26x nog maar het begin is.
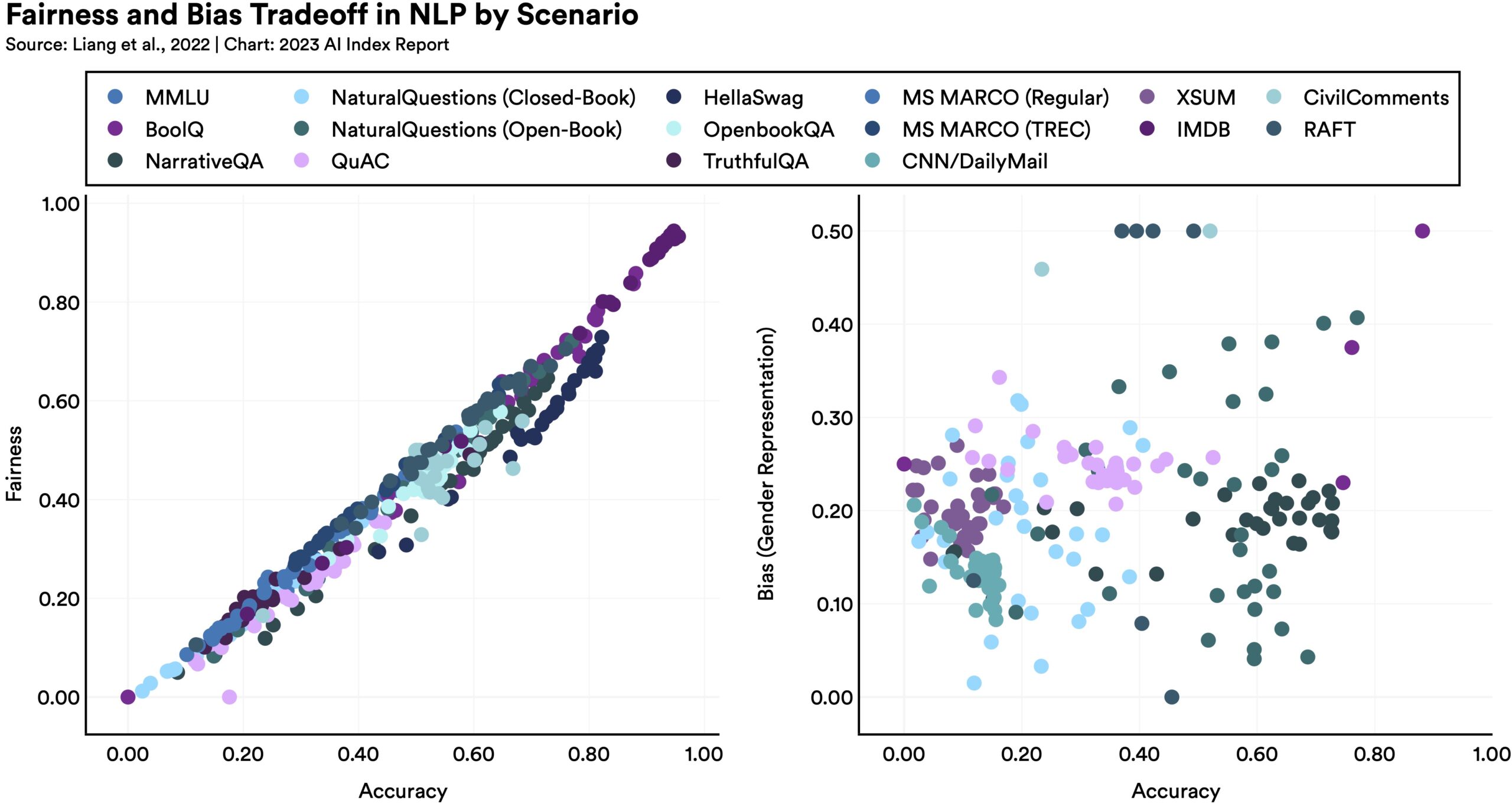
Modellen op de een of andere manier eerlijker of onbevooroordeelder maken, kan onverwachte gevolgen hebben voor andere statistieken, zoals deze grafiek laat zien:
Afbeeldingscredits: Stanford Hallo
Zoals het rapport opmerkt: “Taalkundige modellen die beter presteren op sommige maatstaven van rechtvaardigheid, hebben de neiging om slechtere gendervooroordelen te vertonen.” Waarom? Het is moeilijk te zeggen, maar het laat alleen maar zien dat de verbetering niet zo eenvoudig is als iedereen zou hopen. Er is geen eenvoudige oplossing om deze grote modellen te optimaliseren, deels omdat we niet echt begrijpen hoe ze werken.
Feiten controleren is een gebied dat geschikt lijkt voor AI: nadat het een groot deel van het web heeft geïndexeerd, kan het de gegevens evalueren, het vertrouwen herstellen dat het wordt ondersteund door eerlijke bronnen, enzovoort. Dit is verre van het geval. AI is inderdaad bijzonder slecht in het beoordelen van feiten en het risico is niet dat ze onbetrouwbare auditors worden, maar dat ze zelf krachtige bronnen van verkapte desinformatie worden. Er zijn een aantal onderzoeken en datasets gemaakt om het AI-validatieproces te testen en te verbeteren, maar tot nu toe zijn we nog min of meer waar we begonnen.
Gelukkig is er hier een enorme belangstelling, om de voor de hand liggende reden dat als mensen het gevoel hebben dat ze AI niet vertrouwen, de hele industrie achteruitgaat. Er is een exponentiële toename van inzendingen op de ACM-conferentie over eerlijkheid, verantwoording en transparantie, en bij NeurIPS krijgen kwesties als eerlijkheid, privacy en interpretatie meer aandacht en podiumtijd.
Deze hoogtepunten laten veel details op tafel achter. Het HAI-team heeft echter uitstekend werk verricht door de inhoud samen te stellen, en nadat je hier de belangrijkste dingen hebt bekeken, kun je de volledige paper downloaden en dieper ingaan op elk onderwerp dat je interesseert.